Software for Statistical Analysis of Sample Survey Data
Barbara Lepidus Carlson, Ph.D.
Mathematica Policy Research, Princeton, New Jersey
COPYRIGHT: This article is copyrighted and is not to be used without
proper acknowledgment and citation. It will appear as a chapter in
Encyclopedia of Biostatistics, edited by Peter Armitage and
Theodore Colton (Editors-in-Chief), to be published by John Wiley in summer, 1998 as six
volumes. The article will be in a section titled "Design of
Experiments and Sample Surveys", edited by Paul Levy.
Introduction
A sample survey is a process for collecting data on a sample of
observations which are selected from the population of interest
using a probability-based sample design. In sample surveys, certain
methods are often used to improve the precision and control the
costs of survey data collection. These methods introduce a complexity
to the analysis, which must be accounted for in order to produce
unbiased estimates and their associated levels of precision.
This entry provides a brief introduction to the impact these design
complexities have on the sampling variance and summarizes the
characteristics and availability of software to carry out analysis
on sample survey data.
Complex Sample Designs
Statistical methods for estimating population parameters and their
associated variances are based on assumptions about the characteristics
and underlying distribution of the observations. Statistical
methods in most general-purpose statistical software tacitly assume
that the data meet certain assumptions. Among these assumptions
are that the observations were selected independently and that
each observation had the same probability of being selected.
Data collected through surveys often have sampling schemes that
deviate from these assumptions. For logistical reasons, samples
are often clustered geographically to reduce costs of administering
the survey, and it is not unusual to sample households, then subsample
families and/or persons within selected households. In these
situations, sample members are not selected independently, nor
are their responses likely to be independently distributed.
In addition, a common survey sampling practice is to oversample
certain population subgroups to ensure sufficient representation
in the final sample to support separate analyses. This is particularly
common for certain policy-relevant subgroups, such as ethnic and
racial minorities, the poor, the elderly, and the disabled. In
this situation, sample members do not have equal probabilities
of selection. Adjustments to sampling weights (the inverse of
the probability of selection) to account for nonresponse, as well
as other weighting adjustments (such as poststratification to
known population totals), further exacerbate the disparity in
the weights among sample members.
Impact of Complex Sample Design on Sampling Variance
Because of these deviations from standard assumptions about sampling,
such survey sample designs are often referred to as complex.
While stratification in the sampling process can decrease the
sampling variance, clustering and unequal selection probabilities
generally increase the sampling variance associated with resulting
estimates. Not accounting for the impact of the complex sample
design can lead to an underestimate of the sampling variance associated
with an estimate. So while standard software packages such as
SAS (SAS Institute, Inc. [28]) and SPSS (SPSS, Inc. [30]) can
generally produce an unbiased weighted survey estimate, it is
quite possible to have an underestimate of the precision of such
an estimate when using one of these packages to analyze survey
data.
The magnitude of this effect on the variance is commonly measured
by what is known as the design effect (Kish [18]). The
design effect is the sampling variance of an estimate, accounting
for the complex sample design, divided by the sampling variance
of the same estimate, assuming a sample of equal size had been
selected as a simple random sample. A design effect of unity
indicates that the design had no impact on the variance of the
estimate. A design effect greater than one indicates that the
design has increased the variance, and a design effect less than
one indicates that the design actually decreased the variance
of the estimate. The design effect can be used to determine the
effective sample size, simply by dividing the nominal sample
size by the design effect. The effective sample size gives the
number of observations that would yield an equivalent level of
precision from an independent and identically-distributed (iid)
sample. For example, an estimate from a complex sample of size
1,500 that has a design effect of 1.5 is equivalent (in terms
of precision) to that same estimate from a simple random sample
of size 1,000. The benefits of the complex design in this case
would be weighed against the cost of effectively losing 500 observations.
For complex designs, the exact computation of the variance of
an estimate is not always possible. When estimating a total
or a mean (when the denominator is known), the estimate is in
linear form; that is, 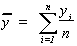 can be expressed
in the form
can be expressed
in the form 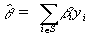 . When an estimate is in
linear form, a standard formula for the mean square error of a
linear estimate can be applied to calculate the variance; however,
for a weighted mean estimate, the form is no longer linear. If
wi is the weight associated with sample member
i, then the weighted mean is calculated as:
. When an estimate is in
linear form, a standard formula for the mean square error of a
linear estimate can be applied to calculate the variance; however,
for a weighted mean estimate, the form is no longer linear. If
wi is the weight associated with sample member
i, then the weighted mean is calculated as:
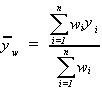 . The mean estimate is now a ratio estimate,
with a random variate in both the
. The mean estimate is now a ratio estimate,
with a random variate in both the
numerator and denominator.
Variance Estimation Methods
Several approaches have historically been used to compute an approximation
of the true variance of an estimate when the sample deviates from
iid assumptions. These techniques fall into two general categories:
(1) the Taylor series linearization technique and (2) replication
techniques. Both of these were first proposed in the literature
for use with survey data in the 1960s. While over the years government
statistical agencies, academic departments, and private survey
organizations implemented their own algorithms and developed their
own software for carrying out these techniques, several software
packages have emerged over the years for public use, first for
mainframe computer applications, and now for use on personal computers
and in other computing environments. The variance estimation
software available to the public use one or the other of the two
general strategies for variance estimation mentioned above. What
follows is a brief description of these two types of techniques.
For more detailed descriptions of these techniques, the reader
is advised to consult the references given. Overviews of these
techniques can be found in Kish and Frankel [21], Bean [1], Kaplan
et al. [17], Wolter [33], Rust [27], and Flyer et al. [12].
Because estimates of interest in sample surveys are nonlinear,
one approach is to linearize such estimates using a Taylor
Series expansion. This approach was first suggested for use with
survey estimates in 1968 by Tepping at the U.S. Bureau of the
Census (Tepping [31]). In essence, the estimate is re-written
in the form of a Taylor's series expansion, and an assumption
is made that all higher-order terms are of negligible size, leaving
only the first-order (linear) portion of the expanded estimate.
A standard formula for the mean square error of a linear estimate
can then be applied to the linearized version to approximate the
variance of the estimate. This approximation works well to the
extent that the assumption regarding the higher-order terms is
correct. See also Woodruff [34]. Note that, with this approach
to variance estimation, a separate formula for the linearized
estimate must be developed for each type of statistical estimator.
Most survey data analysis software includes the most widely
used estimates (such as means, proportions, ratios, and regression
coefficients). Binder [2] introduced a general approach that
can be used to derive Taylor Series approximations for a wide
range of estimators, including Cox proportional hazards and logistic
regression coefficients.
Replication techniques are a family of approaches that take repeated
subsamples, or replicates, from the data, re-compute the
weighted survey estimate for each replicate, and then compute
the variance based on the deviations of these replicate estimates
from the full-sample estimate. This approach was first suggested
in for use with survey data in 1966 by McCarthy at Cornell University
as part of his work with the National Center for Health Statistics
(McCarthy [24]). The most commonly-used replication techniques
are the balanced repeated replication (BRR) method and
the jackknife method. Robert Fay at the U.S. Bureau of
the Census has developed his own replication technique for this
purpose as well. Other techniques less commonly used for this
purpose are bootstrapping (Rao and Wu [26]) and the random group
method (Hansen et al. [15]). All replication techniques require
the computation of a set of replicate weights, which are the analysis
weights re-calculated for each of the replicates selected so that
each replicate appropriately represents same population as the
full sample. Such computing-intensive techniques became practical
only as the computing capacity on mainframes and then personal
computers increased. Unlike the Taylor Series method, replication
methods do not require the derivation of variance formulas for
each statistical estimate because the approximation is a function
of the sample, not of the estimate.
With balanced repeated replication (also known as balanced half-sampling),
forming a replicate involves dividing each sampling stratum into
two primary sampling units (PSUs), and randomly selecting one
of the two PSUs in each stratum to represent the entire stratum
(see Kish and Frankel [19] and [20], and McCarthy [25]). The
jackknife repeated replication approach involves removing one
stratum at a time to create each replicate (see Frankel [13] and
Tukey [32]). Fay's method is similar to the BRR approach, except
that, instead of selecting one of two PSUs in each stratum, the
weights of one of the two PSUs in each stratum are multiplied
by a factor k between 0 and 2 and the weights of the other
PSU are multiplied by a factor of 2 - k (Fay [11]). See
also Dippo et al. [9] and Fay [10] for a discussion of replication
methods.
Software Packages
At the time this is being written (summer of 1996), several packages
are available to the public designed specifically for use with
sample survey data. Those that use the Taylor Series approach
to variance estimation include SUDAAN (developed by Babu Shah
and others at Research Triangle Institute), PC Carp (developed
by Wayne Fuller at Iowa State University and M.A. Hidirouglou
at Statistics Canada), and Stata (Stata Corporation, College Station,
TX), which added this capability to an existing general-purpose
statistical package in 1995. Those packages that use replication
approaches to variance estimation include WesVar and WesVarPC
(developed by David Morganstein and others at Westat) and VPLX
(developed in 1989 by Robert Fay at the U.S. Bureau of the Census).
WesVarPC has the option of one of several replication techniques,
including BRR, two variants of the jackknife approach, and Fay's
method. Two of the popular general-purpose statistical packages
(SAS and SPSS) claim to be developing the capacity to analyze
complex sample survey data in future versions of their software.
The University of Michigan's Institute for Social Research, which
previously developed variance estimation procedures for use with
its mainframe package Osiris IV (&PSALMS, &REPERR, etc.)
(Lepkowski et al. [23]), which it no longer supports, is in the
early stages of developing a new replication-based package that
would be available over the Internet. The U.S. Centers for
Disease Control have produced a program called CSAMPLE within
its EPI-INFO (Dean et al. [8]) software package that uses the
Taylor Series methodology to estimate variances. This package
is targeted at epidemiologists and other public health researchers
who use the World Health Organization's EPI cluster survey methodology
(Brogan et al. [4]). Many governmental statistical agencies (including
those in the U. S., Canada, Sweden, Holland, and France) have
developed their own sample survey software to meet their needs.
This software is sometimes available from the agencies for use
by others, but not marketed as such.
Issues in Selecting and Using Sample Survey Software
There are several ways to evaluate the qualities of such software
packages when deciding which one to use. The user must first
evaluate his or her analytical needs first, such as computing
environment and statistical procedures needed, and then decide
among those that will be the easiest to use. None of the existing
packages meet all of the recommended criteria in the following
paragraphs. For the packages mentioned above, or any that use
either of the two variance estimation approaches described, there
is no need for the user to be concerned about whether the method
used to estimate the variances is statistically sound when choosing
among packages. Both the Taylor series linearization approach
and replication methods were derived from well-accepted approaches
previously applied to other statistical problems. Each has certain
circumstances in which its approximation of the variance is better
than that of the other, and certain replication techniques work
better than others, depending on the sample design (Brillinger
[3], Rust [27]). Empirical evaluations (using national survey
data such as the Current Population Survey and the National Health
Interview Survey) have shown little difference in the estimates
of the variance using the different approaches (Frankel [13],
Kish and Frankel [21], Bean [1]).
From a practical standpoint, the software must work in the computing
environment in which the user works. If the user works primarily
on a mainframe or on a Macintosh, s/he will find that some of
the software packages are available only for use on DOS- or Windows-based
personal computers. And if one routinely works with certain types
of statistical estimates, such as those resulting from multivariate
logistic regression or other nonlinear models, the user may find
that many of the software packages do not have the full array
of statistical procedures that are currently available in the
traditional statistical software packages such as SAS and SPSS.
In addition, the software package should be able to import the
user's data sets, whether they were created using standard statistical,
database, or spreadsheet packages, as well as text (ASCII) files.
The software package should be relatively easy to use; however,
there is a tradeoff between this ease of use and the propensity
for using the software inappropriately. Some packages are relatively
straightforward to use, with a menu-driven or Windows-type approach,
enabling someone unfamiliar with the underlying assumptions to
unknowingly get estimates that are inappropriate for his or her
design. Other packages are less "user-friendly," and
require writing lines of code to be submitted as a batch job,
which generally requires the user to learn more up front about
the package itself. However, when a large number of similar analyses
will be run, it is often easier to run analyses in batch mode
than through a menu-driven or Windows-type mode. Software packages
should have an option for a batch mode of execution.
In any case, user support should be readily available through
thorough and well-written documentation, helpful error messages,
a complete set of "help" screens, and prompt assistance
from the software provider via telephone and/or electronic mail.
It should be kept in mind that most packages were initially developed
to accommodate a certain type of sample design and a certain type
of user (perhaps a particular government agency and a particular
survey). This tends to make the packages less user-friendly to
those with different data and analysis needs. Packages should
have the capacity to handle nonstandard designs, or provide guidance
in the documentation as to the most appropriate design to specify
in these circumstances and what the consequences are (such as
an overestimate of the variance). On the other hand, for even
the most sophisticated packages, it should not be cumbersome to
specify a relatively simple design. The statistical package should
provide technical documentation, including the formulas used for
point estimates and the variance estimates.
Currently, it is commonly the case that a user creates a data
file using SAS, SPSS, or some other general-purpose statistical
package, and then imports the file into one of these specialized
packages. The specialized packages generally do not allow for
much data editing, variable construction, recoding, or sorting.
Depending on the specialized package and the estimates desired,
it may be necessary to then take the output from the specialized
package and carry out further data manipulation in the original
general-purpose (or yet another) statistical package to obtain
the needed estimates. Sometimes, to carry out subgroup analyses,
it is necessary to create separate files for each subgroup and
go through the entire process for each subgroup. Ideally, variance
estimation capabilities for sample survey data would be built
into most of the general-purpose statistical packages, but such
options are not yet available.
Several of the software packages currently available or under
development are being made available free to users via the Internet,
but sometimes offer less in the way of support and training.
Others can run over $1,000 (U.S.) for a single-use license, presumably
providing more comprehensive technical support and training for
users and notification regarding upgrades. Training itself can
be in the form of formal in-person training courses (which can
be expensive), Internet-based training, or documentation that
is comprehensive enough to use as a training manual. In many
cases, documentation is merely a reference manual, and the user
must learn how to use the package from a formal training course
or by working with someone familiar with the package.
The more difficult and/or expensive a software package is to obtain,
learn, and use, the less likely analysts are going to use it.
Many analysts do not even realize they should use weights when
deriving estimates, let alone use specialized software to correctly
estimate the variances. It should be made clear to users of public
use data files through the accompanying documentation that it
is necessary to account for the design when creating estimates.
If it is impossible for confidentiality reasons to provide variables
on these files that designate the stratum, PSU, and weight for
each observation, then the agency, company, or department providing
the file should be willing and able to provide standard errors
or design effects for certain variables on request, or should
provide generalized variance curves, tables of standard errors
or design effects for a wide array of variables, or at the very
least provide the average design effect for certain types of variables
for certain subgroups (Burt and Cohen [5]). If there are no such
confidentiality concerns, then the public use file should come
with variables for stratum, PSU, and weight, that are clearly
marked as such. Ideally, such data files would come with a set
of replicate weights as well. It is unreasonable to expect secondary
data users to derive a rather large set of replicate weights on
their own. At least one package, WesVarPC, has a procedure that
can be used create replicate weights under certain circumstances.
(It cannot create replicate weights that adjust for unit nonresponse
or other weighting adjustments other than poststratification.)
In general, to run any of these specialized packages, one needs
to specify variables on the file that correspond to sampling stratum,
PSU, and analysis weight. In addition, the file needs to be
sorted by stratum and then PSU within stratum. Further, there
generally has to be at least two PSUs in each stratum. (If this
is not the case, then the user needs to collapse across strata.)
The user should have a good understanding of the design. Was
stratification employed? How many sampling stages were there?
At each stage of sampling, were the units selected with or without
replacement? Were the units selected with equal probability or
was there disproportionate sampling (such as oversampling or selection
with probability proportional to size)? The user should also
know which variables are continuous or interval, versus categorical
or ordinal. For categorical or ordinal variables, the user should
know the number of categories of each.
Most of the specialized software packages compute means, totals,
proportions, ratios, and linear regression models. Many also
have the capacity to estimate logistic regression, loglinear,
and other types of models. At least two of the packages (SUDAAN
and WesVar) were initially developed as SAS procedures, so the
syntax in batch mode is similar to that of SAS. Some of the packages
also allow for the specification of both with-replacement and
without-replacement designs, employing a finite-population-correction
factor in the latter.
Several papers have been published that compare the various software
packages. Because many of these packages have evolved over time,
many of the criticisms and comparisons found in these papers are
no longer valid. (See Kaplan et al. [17], Cohen et al. [7], and
Carlson et al. [6].)
There is an ongoing debate as to whether the sample design must
be considered when deriving statistical models (as opposed to
estimates of means, proportions, totals, and ratios) based on
sample survey data. Analysts interested in using statistical
techniques such as linear regression, logistic regression, survival
analysis, or categorical data analysis on survey data are divided
as to whether they feel it is necessary to use specialized software.
The model-based analysts argue that, as long as the model is
specified correctly, they can proceed without recognizing aspects
of the survey design (such as stratification, clustering, and
unequal selection probabilities), and can therefore use standard
statistical packages. The design-based analysts argue to the
contrary that it is important to account for the survey design
when estimating models. The debate between these two factions
has been ongoing for quite awhile and is not likely to be resolved
soon (Groves [14], Skinner et al. [29], Korn and Graubard [22],
Hansen et al. [16]). A compromise position adopted by some is
to use standard statistical software in modeling analyses, but
to incorporate into the model the variables that were used to
define the strata, the PSUs and the weights.
Contact information for the providers of the specialized software
mentioned are found after the references under the name of the
software.
References
1. Bean J (1975), "Distribution and Properties of Variance
Estimators for Complex Multistage Probability Samples: An Empirical
Distribution," Vital and Health Statistics, Series
2 Number 65, National Center for Health Statistics.
2. Binder DA (1983), "On the Variances of Asymptotically
Normal Estimators from Complex Surveys," International
Statistical Review 51, 279-92.
3. Brillinger DR (1977), "Approximate Estimation of the
Standard Errors of Complex Statistics Based on Sample Surveys."
New Zealand Statistician 11(2), 35-41.
4. Brogan D, E Flagg, M Deming, and R Waldman (1994), "Increasing
the Accuracy of the Expanded Programme on Immunization's Cluster
Survey Design," Annals of Epidemiology 4(4),
302-311.
5. Burt VL and SB Cohen (1984), "A Comparison of Alternative
Variance Estimation Strategies for Complex Survey Data."
Proceedings of the American Statistical Association Survey
Research Methods Section.
6. Carlson BL, AE Johnson, and SB Cohen (1993), "An Evaluation
of the Use of Personal Computers for Variance Estimation with
Complex Survey Data," Journal of Official Statistics
9(4), 795-814.
7. Cohen SB, JA Xanthapoulos, and GK Jones (1988), "An Evaluation
of Statistical Software Procedures Approriate for the Regression
Analysis of Complex Survey Data." Journal of Official
Statistics 4,17-34.
8. Dean AG, JA Dean, D Coulombier, KA Brendel, DC Smith, AH Burton,
RC Dicker, K Sullivan, RF Fagan, and TG Arner (1995). Epi
Info, Vergion 6: A Word Processing, Database, and Statistics Program
for Public Health on IBM-Compatible Microcomputers. Centers
for Disease Control and Prevention. Atlanta, GA.
9. Dippo CS, RE Fay, and DH Morganstein (1984), "Computing
Variances from Complex Samples with Replicate Weights."
Proceedings of the American Statistical Association Survey
Research Methods Section.
10. Fay RE (1984), "Some Properties of Estimates of Variance
Based on Replication Methods." Proceedings of the American
Statistical Association Survey Research Methods Section.
11. Fay RE (1990), "VPLX: Variance Estimates for Complex
Samples." Proceedings of the American Statistical Association
Survey Research Methods Section.
12. Flyer P, K Rust, and D Morganstein (1989), "Complex
Survey Variance Estimation and Contingency Table Analysis Using
Replication." Proceedings of the American Statistical
Association Survey Research Methods Section.
13. Frankel MR (1971), Inference from Survey Samples.
Ann Arbor, MI: Institute for Social Research, the University
of Michigan.
14. Groves R (1989), Survey Errors and Survey Costs.
New York: John Wiley.
15. Hansen MH, WN Hurwitz, and WG Madow (1953), Sample Survey
Methods and Theory, Volume I: Methods and Applications. New
York: Wiley (Section 10.16).
16. Hansen MH, WG Madow, and BJ Tepping (1983), "An Evaluation
of Model-Dependent and Probability-Sampling Inferences in Sample
Surveys," Journal of the American Statistical Association
78(384), 776-793.
17. Kaplan B, I Francis, and J Sedransk (1979), "A Comparison
of Methods and Programs for Computing Variances of Estimators
from Complex Sample Surveys." Proceedings of the American
Statistical Association Survey Research Methods Section (pp.
97-100).
18. Kish L (1965), Survey Sampling, New York: John Wiley
and Sons, p. 162.
19. Kish L and M Frankel (1968), "Balanced Repeated Replications
for Analytical Statistics," Proceedings of the American
Statistical Association Social Statistics Section, pp. 2-10.
20. Kish L and MR Frankel (1970), "Balanced Repeated Replications
for Standard Errors," Journal of the American Statistical
Association 65(331), 1071-1094.
21. Kish L and MR Frankel (1974), "Inference from Complex
Samples," Journal of the Royal Statistical Society
B(36), 1-37.
22. Korn E and B Graubard (1995), "Analysis of Large Health
Surveys: Accounting for the Sample Design," Journal of
the Royal Statistical Society A(158), 263-295.
23. Lepkowski JM, JA Bromberg, and JR Landis (1981), "A
Program for the Analysis of Multivariate Categorical Data from
Complex Sample Surveys." Proceedings of the American
Statistical Association Statistical Computing Section.
24. McCarthy P (1966), "Replication: An Approach to the
Analysis of Data From Complex Surveys," Vital and Health
Statistics, Series 2, Number 14, National Center for Health
Statistics.
25. McCarthy P (1969), "Pseudoreplication: Further Evaluation
and Application of the Balanced Half-Sample Technique," Vital
and Health Statistics, Series 2, Number 31, National
Center for Health Statistics.
26. Rao JNK and CFJ Wu (1984), "Bootstrap Inference for
Sample Surveys." Proceedings of the American Statistical
Association Survey Research Methods Section.
27. Rust K (1985), "Variance Estimation for Complex Estimators
in Sample Surveys," Journal of Official Statistics
1(4), 381-397.
28. SAS Institute, Inc. (1994), SAS System for Windows, Release
6.10 Edition. Cary, NC.
29. Skinner CJ, D Holt, and TMF Smith (1989). Analysis of
Complex Surveys. New York: John Wiley.
30. SPSS, Inc. (1988), SPSS/PC+ V2.0 Base Manual. Chicago,
IL.
31. Tepping BJ (1968), "Variance Estimation in Complex Surveys,"
Proceedings of the American Statistical Association Social
Statistics Section, pp. 11-18.
32. Tukey JW (1958), "Bias and Confidence in Not-quite Large
Samples: Abstract." Annals of Mathematical Statistics
29, 614.
33. Wolter KM (1985), Introduction to Variance Estimation.
New York: Springer-Verlag.
34. Woodruff RS (1971), "A Simple Method for Approximating
the Variance of a Complicated Estimate," Journal of the
American Statistical Association 66(334), 411-414.
Bibliography: Software Documentation, References, and Contact
Information
PC Carp
Fuller WA (1975), "Regression Analysis for Sample Surveys,"
Sankhya C, 37, pp. 117-132.
Fuller WA, Kennedy W, Schell D, Sullivan G, and Park HJ (1989).
PC CARP. Ames, Iowa: Statistical Laboratory, Iowa State
University.
Hidirouglou MA (1974), "Estimation of Regression Parameters
for Finite Populations," Unpublished Ph.D. thesis. Ames,
Iowa: Iowa State University.
Contact: Statistical Laboratory, Institute for Social Research,
Iowa State University at (515) 294-5242 to purchase software.
Available for use on personal computers running under DOS.
Stata
Stata Corporation (1996), "Stata Technical Bulletin,"
STB-31, College Station, TX, pp. 3-42.
Contact: Stata Corporation, College Station, TX at (800) STATAPC
(782-8272) or by Internet at Stata@Stata.com to purchase software.
Available for use on personal computer (Windows, DOS, Mac) or
workstation (DEC, SPARC, and others).
SUDAAN
Shah BV, Folsom RE, LaVange LM, Boyle KE, Wheeless SC, and Williams
RL (1993), "Statistical Methods and Mathematical Algorithms
Used in SUDAAN." Research Triangle Park, NC: Research Triangle
Institute.
Shah BV, Barnwell BG, and Bieler GS (1996), "SUDAAN User's
Manual, Version 6.4, Second Edition." Research Triangle
Park, NC: Research Triangle Institute.
Contact: Research Triangle Institute at (919) 541-6602 or by Internet
at SUDAAN@rti.org or http://www.rti.org/patents/sudaan.html to
purchase software. Available for use on mainframe (VAX, IBM,
DEC), workstation (VAX, SunOS, RISC-6000, DEC), or personal computer
(Windows or DOS).
VPLX
Fay RE (1990), "VPLX: Variance Estimates for Complex Samples."
Proceedings of the American Statistical Association Survey Research
Methods Section.
Contact: VPLX and its documentation are available free of charge
on the U.S. Bureau of the Census Web site: http://www.census.gov.
It is available in executable format for use on personal computers
(DOS), VAX VMS, and UNIX-based workstations. It is portable to
other systems as well--a FORTRAN version is available to copy
and compile on any system.
WesVarPC
Brick JM, Broene P, James P, and Severynse J (1996), "A User's
Guide to WesVarPC." Rockville, MD: Westat, Inc.
Flyer P, Rust K, and Morganstein D (1989), "Complex Survey
Variance Estimation and Contingency Table Analysis Using Replication."
Proceedings of the American Statistical Association Survey Research
Methods Section.
Contact: WesVarPC and its documentation are available free of
charge on Westat's Web site: http://www.westat.com or at WesVar@Westat.com.
It is available for use on Windows-based personal computers.
WesVar, WesReg, and WesLog are mainframe programs available free
of charge from Westat.